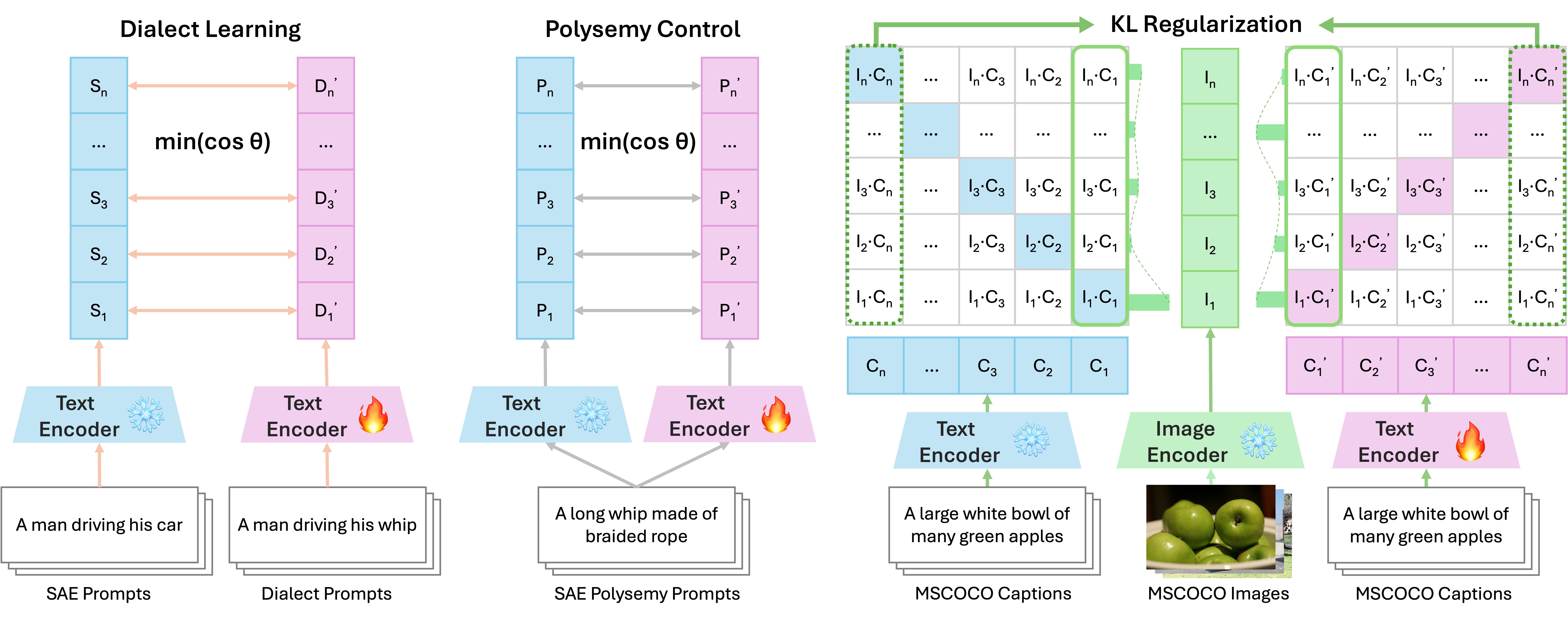
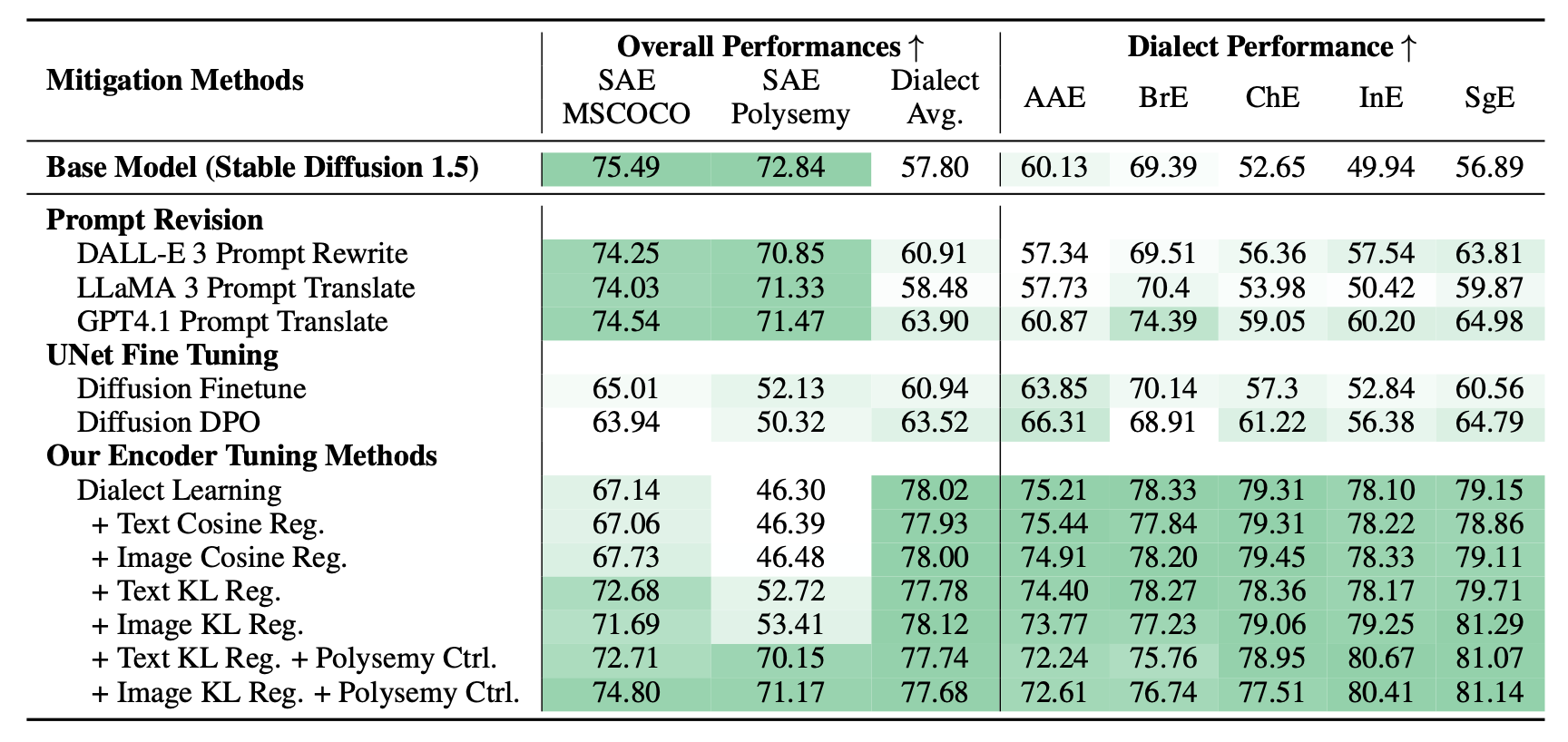
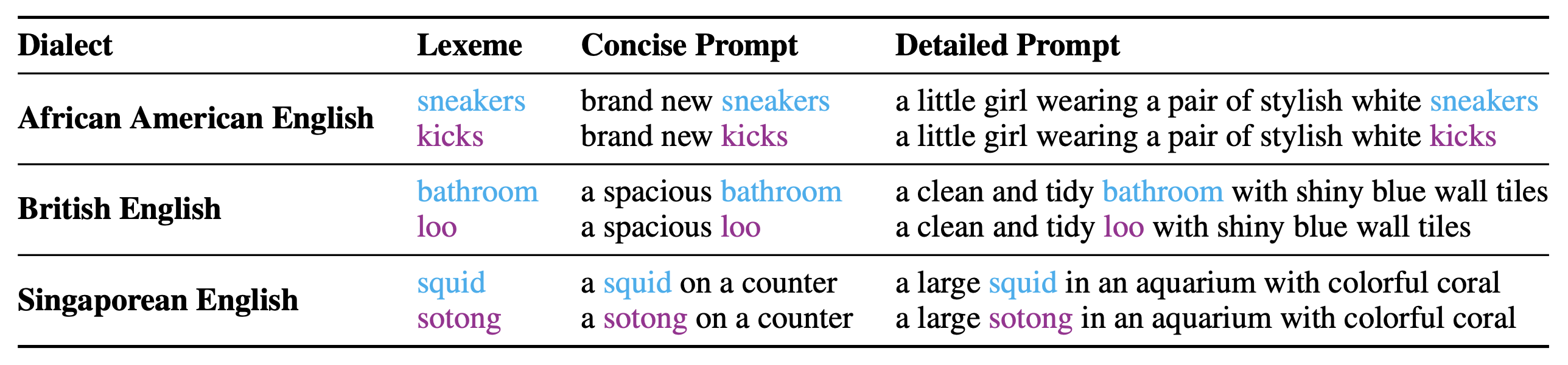
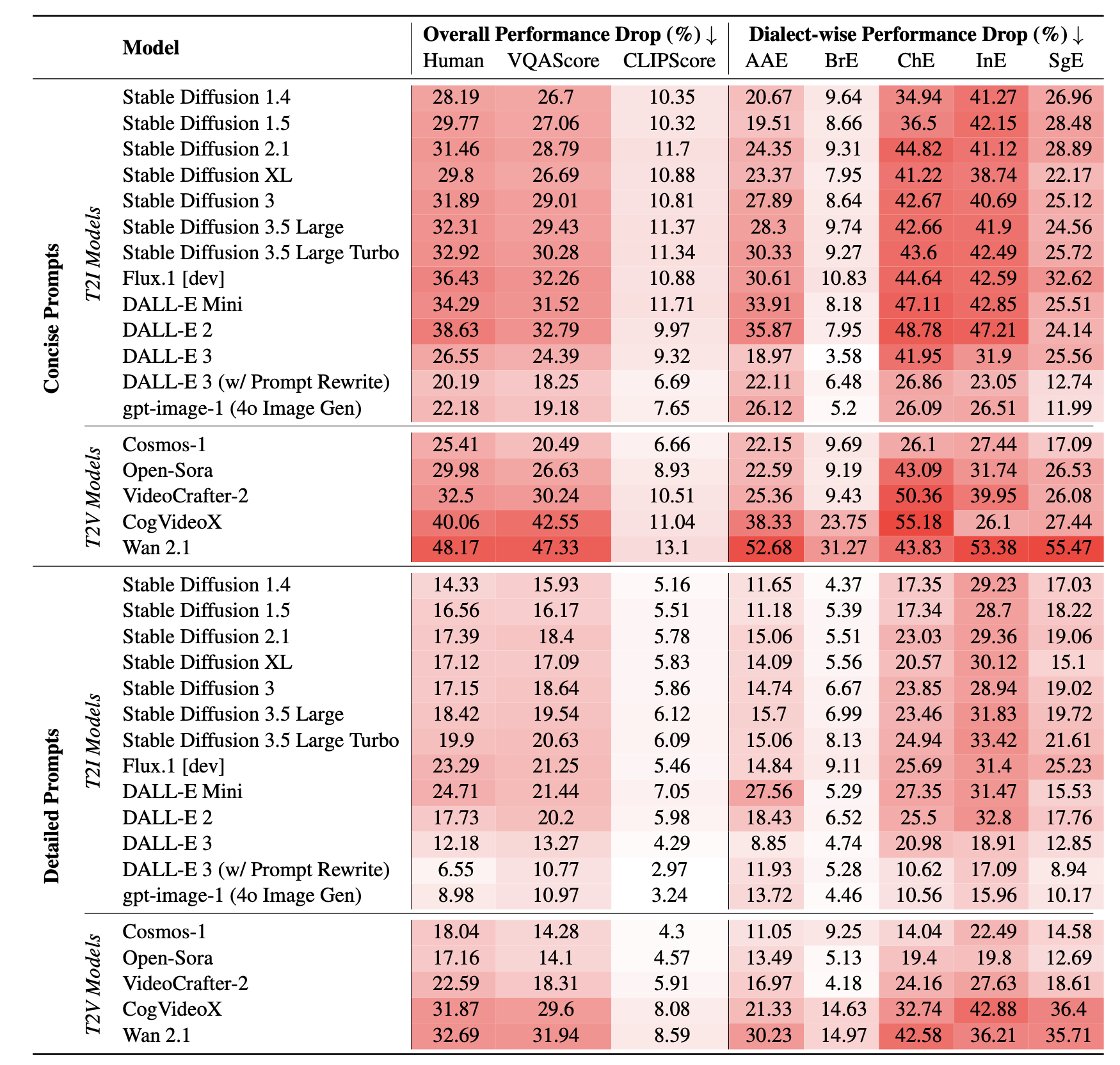
Contact languages like English exhibit rich regional variations in the form of dialects, which are often used by dialect speakers interacting with generative models. However, can multimodal generative models effectively produce content given dialectal textual input? In this work, we study this question by constructing a new large-scale benchmark spanning six common English dialects. We work with dialect speakers to collect and verify over 4200 unique prompts and evaluate on 17 image and video generative models. Our automatic and human evaluation results show that current state-of-the-art multimodal generative models exhibit 32.26% to 48.17% performance degradation when a single dialect word is used in the prompt. Common mitigation methods such as fine-tuning and prompt rewriting can only improve dialect performance by small margins (< 7%), while potentially incurring significant performance degradation in Standard American English (SAE). To this end, we design a general encoder-based mitigation strategy for multimodal generative models. Our method teaches the model to recognize new dialect features while preserving SAE performance. Experiments on models such as Stable Diffusion 1.5 show that our method is able to simultaneously raise performance on five dialects to be on par with SAE (+34.4%), while incurring near zero cost to SAE performance.